The Trillion Dollar Chart
Disclaimers
- This is an article about AI. If you’re tired of talking about AI please close this tab and don’t yell at me!
- I’m not an economist, or an AI expert, just a chart enthusiast and programmer.
- In this post, I focus on OpenAI’s progress to simplify the story. There are other labs working on related work, and the GPT series of models are far from the only important LLMs. OpenAI’s model performance is not the only sign of progress in AI.
Intro
In 2020, one of the most important papers in the development of AI was published: Scaling Laws for Neural Language Models, which came from a group at OpenAI.
This paper showed with just a few charts incredibly compelling evidence that increasing the size of large language models would increase their performance. This paper was a large driver in the creation of GPT-3 and today’s LLM revolution, and caused the movement of trillions of dollars in the stock market.
I want to explore why following the results of this paper to justify building models of ever increasing size was both right and wrong, and how the breakdown of the “scaling laws” that we observe today is a really big deal.
Just Look At This Chart
First, let’s look at one of the paper’s charts, Figure 6.
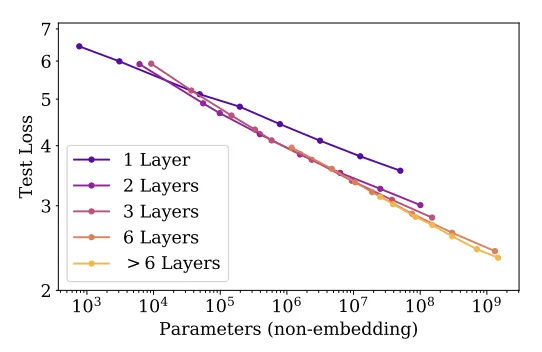
In Figure 6, we see some extremely, extremely straight lines of empirical data. The X axis is a logarithmic scale (each bump is 10x the last) for the size of models. On the Y-axis is “test loss”, which is a fairly complicated statistic for how well the model predicts words. Lower “loss” means the model is better at predicting words. (That’s a drastic simplification). We later learned that test loss is related to model “intelligence”, but it’s worth noting that it’s not a benchmark that aims to measure that in any specific way. In 2020, it was too early to even consider a model’s “intelligence”.
Based on the amazing straightness of these lines, I think it is extremely fair to bet that increasing parameters to 10^10 and beyond would result in further improvement in the test loss metric. This is really cool, and is why Open AI trained GPT-3, and later GPT-4. It worked, and it was incredible.
Let’s summarize the situation:
- The scaling law paper shows a strong relationship between model size and performance
- OpenAI makes a big model (GPT-3), and it’s shockingly good.
- OpenAI makes an even bigger model (GPT-4), and it’s truly incredible, feeling to many spectators (myself included) like science fiction.
- Conclusion: OpenAI (and the rest of the industry) should race to make even bigger models
On the day that GPT-4 came out, this reasoning was so compelling and so exciting that it set off a chain of events that has moved trillions of dollars.
What Happened Next
Everyone saw GPT-4, and everyone in tech noticed. OpenAI wasn’t the only company looking to build models, so in parallel multiple companies began working on creating the largest models they could, as quickly as possible.
If the scaling laws held, the ramifications would be unprecedented. It could be feasible to automate all knowledge work, drastically accelerate scientific research, etc. All by following the lines predicted in a few charts!
To do this, OpenAI and other labs needed compute infrastructure. This led to an absolute explosion in data center spending, in particular by the cloud hyperscalers (Amazon, Google, Microsoft), to the benefit of their preferred GPU vendor, Nvidia.
Below is a chart of Nvidia’s stock price over the past 5 years. In that time, the value of $NVDA has increased by over 1000%, making it the most valuable company in the world with a market capitalization of over 4 trillion dollars.
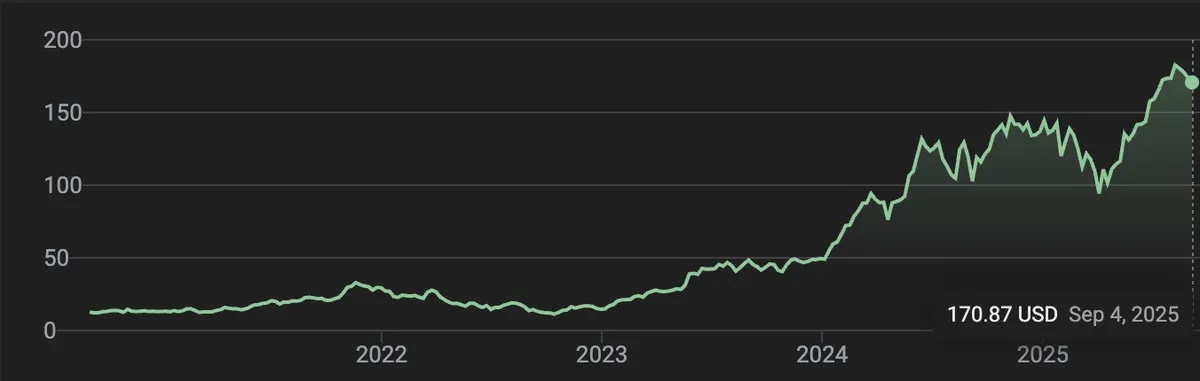
There are other factors at play, but I would argue that Figure 6 and its peers are responsible for a large portion of those 4 trillion dollars.
So the world bought a lot of GPUs. What happened next?
The Scaling Laws Quietly Stopped Working
Remember GPT-4.5? I’d forgive you if you didn’t, because it wasn’t a qualitative leap from GPT-4 in perceived performance. Here is OpenAI’s conclusion from the GPT-4.5 launch. They mention an order of magnitude of compute (remember Figure 6 from before), but nobody talks about the “GPT-4.5 moment” in the way they talk about the launch of GPT-4.
With every new order of magnitude of compute comes novel capabilities. GPT‑4.5 is a model at the frontier of what is possible in unsupervised learning. We continue to be surprised by the creativity of the community in uncovering new abilities and unexpected use cases. With GPT‑4.5, we invite you to explore the frontier of unsupervised learning and uncover novel capabilities with us.
February 27, 2025, the day of this announcement, was in my eyes the moment the party stopped. As mentioned before, the original scaling law paper talked about “test loss”, not “model intelligence”. So, the scaling law may have actually still held here (we don’t know if it did), but we do know that an order of magnitude increase in model size didn’t lead to a drastic improvement in real world performance.
When GPT-4 came out, it seemed as though we were on a train headed directly towards AI systems comparable to those we saw in science fiction, based largely on scaling of model size. Based on the qualitative performance of GPT-4, I actually think it was rational to take a bet on riding the train, and I’ll admit that I was a happy ticket holder until recently.
Where Are We Now
It’s September 2025, and we’re fresh off the launch of GPT-5, which, like GPT-4.5, did not lead to nearly the same jump in performance as GPT-3 to GPT-4.
GPT-5 was an attempt to use other techniques, like increasing how many tokens the model generates before showing a user an answer to improve performance. This type of technique, called “reasoning”, has been a major focus of OpenAI and the other labs for the past year or so, and is further evidence of the diminishing returns of scaling in the sense described in the original paper.
We now need to take a step back. The scaling law train ride is over. We can still be excited about AI, but we have to admit that for more progress to be made, AI labs need to invent new techniques. There is no fast ride to progress based on scaling alone.
Will the inventions we need to make progress come? Big tech is certainly pouring vast resources into trying to make said progress, but there’s really no guarantee. Science and engineering are hard, and we need to remember that GPT-3 and GPT-4 were a complete surprise to almost everyone.
So, what happens to the trillions of dollars we’ve moved? Without the need for orders of magnitude more compute to train models of increasing size, can Nvidia still show the growth numbers needed to justify its valuation? What about the AI data center companies, the AI model labs, the AI startups, and everyone else who bet on the scaling law?
There’s no simple chart that can point us in a straight line to the answer.